Studio 7B
Names
Open questions.md and list the names of everyone in your group.
Studio 7A
If you didn’t complete the implementation of xor last week (Studio 7A), complete it first. (Just the testbench part)
Micro Architectures & Execution
Consider the following segment of code for the next several parts:
mv t0, a0 # t0 = start
add t1, a1, a1 # t1 = 2x a1
add t1, t1, t1 # t1 = 4x a1 (sll a1, a1, 2 would also work)
add t1, a0, t1 # t1 = end (inclusive)
mv a2, zero # Init sum
loop:
lw t2, 0(t0)
add a2, a2, t2
addi t0, t0, 4 # Move to next
blt t0, t1, loop
Single-Cycle CPU
Formula: Come up with a formula for the time taken in terms of the array size ($n$ words) assuming this is running on a single-cycle RISC-V CPU operating at 6MHz (i.e., Homework 7A’s processor).
Specific Instance: How long will it take if $n$ is 100?
Multi-Cycle CPU
Recall the multi-cycle model’s state machine:
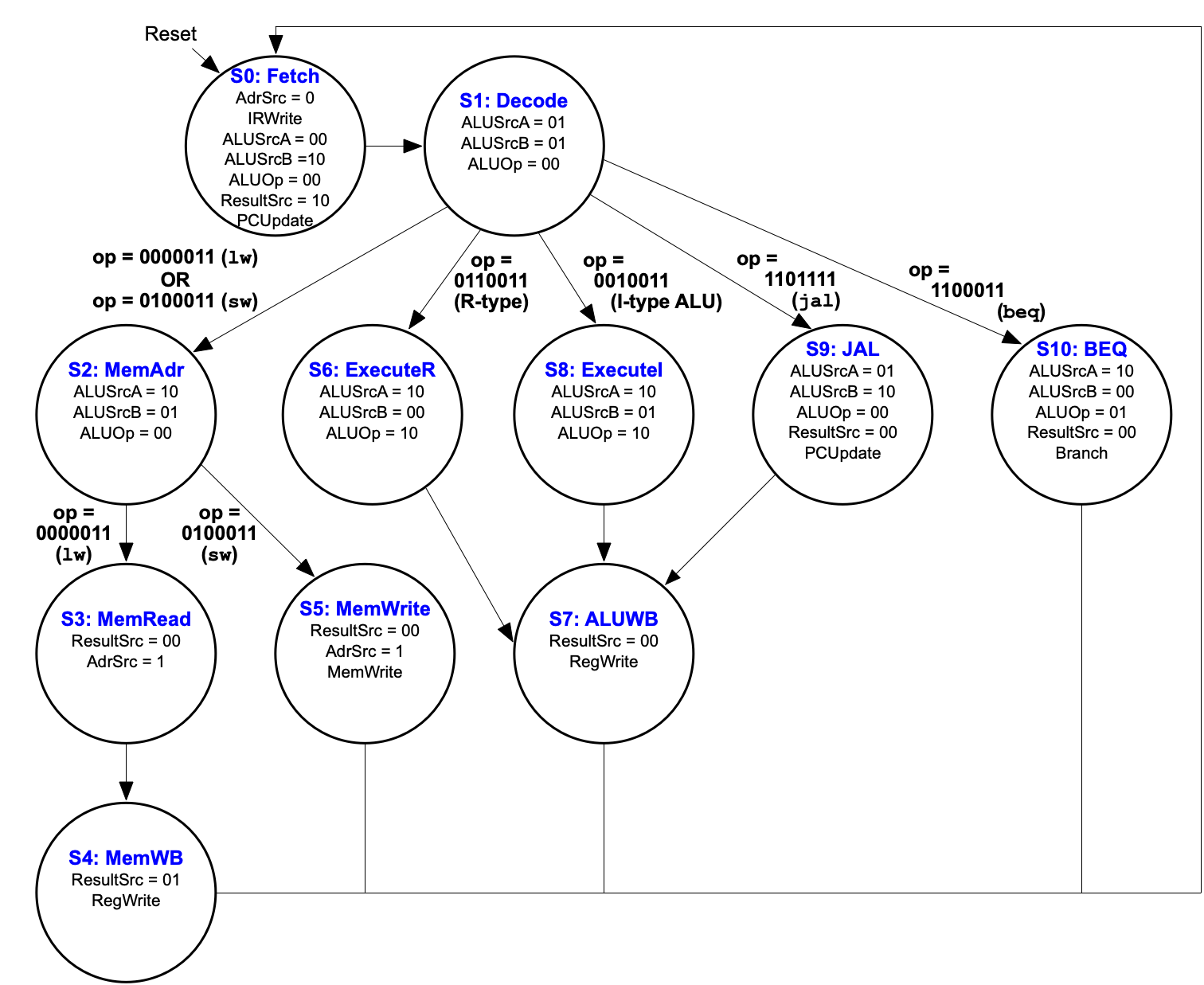
Formula: Come up with a formula for the time taken in terms of the array size ($n$ words) assuming this is running on this multi-cycle RISC-V CPU operating at 24MHz?
Specific Instance: How long will it take if $n$ is 100?
5-stage Pipeline
One of the variations of the RISC-V 5-stage pipeline supports data hazards via forwarding and/or stalls:
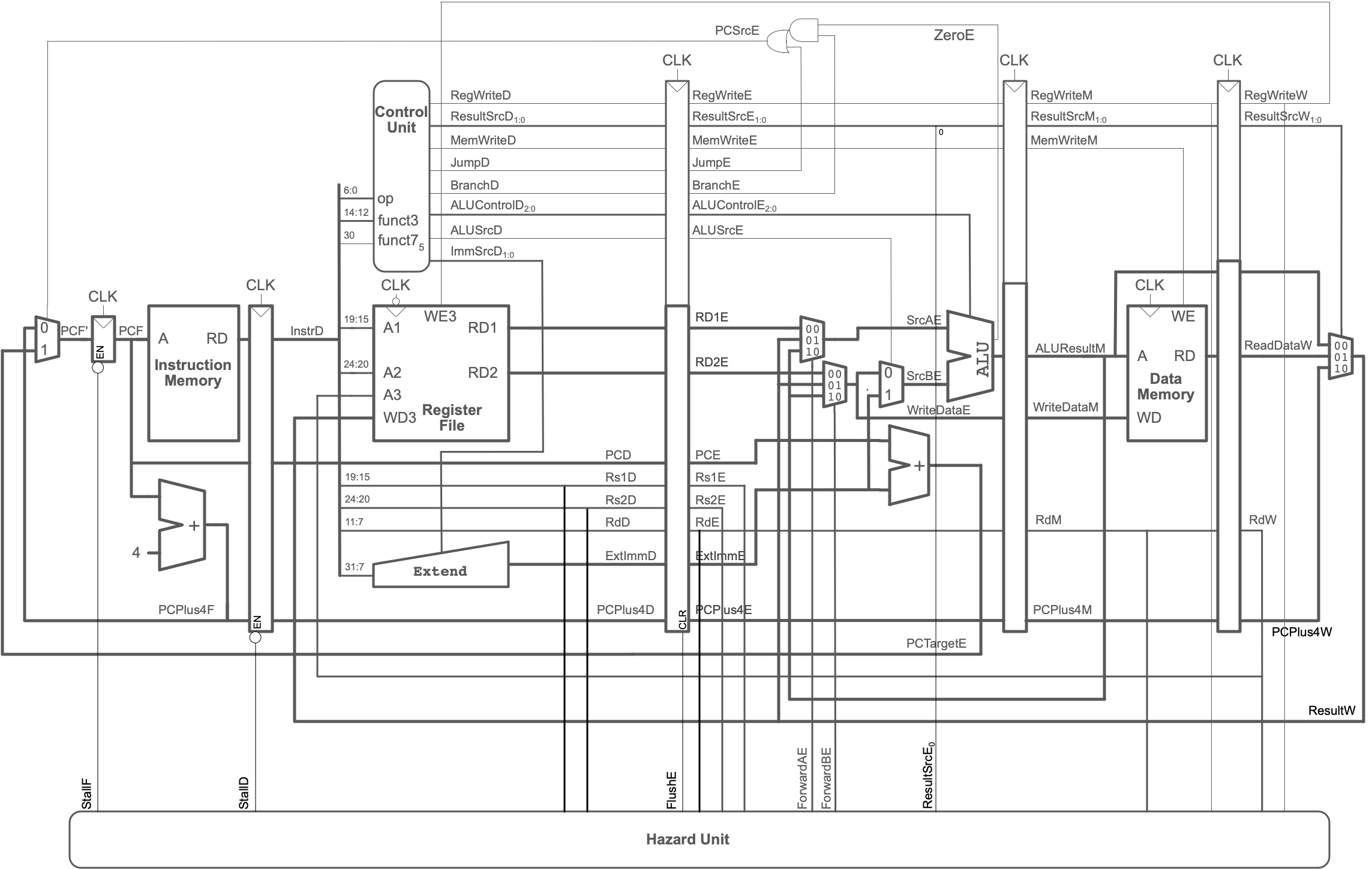
Explain what is meant by a “Data Hazard” and how this CPU design resolves them (forwarding and stalls and and example of when each is needed).
What data hazards exist in this program and how can each be resolved (forwarding? Or stalls? How many stalls?)?
Formula: Come up with an approximate formula for the time taken in terms of the array size ($n$ words) assuming this is running on this 5-stage pipeline RISC-V CPU (support for data hazards via forwarding and stalls) operating at 24MHz (Assume it has a perfect branch predictor — there are no control hazards, but account for the data hazards)?
Specific Instance: How long will it take if $n$ is 100?
More Complex Execution
Assume instead you were asked to analyze this updated version of the code:
mv t0, a0 # t0 = start
add t1, a1, a1 # t1 = 2x a1
add t1, t1, t1 # t1 = 4x a1 (sll a1, a1, 2 would also work)
add t1, a0, t1 # t1 = end (inclusive)
# use first value as min and max
lw a0, 0(t0) # Init min
mv a1, a0 # Init max
mv a2, zero # Init sum
loop:
lw t2, 0(t0)
bge t2, a0, updateSum
mv a0, t2 # Update min
updateSum:
add a2, a2, t2
addi t0, t0, 4 # Move to next
blt t0, t1, loop
Could the approach(es) you’ve taken so far always give an exact answer without additional information (FYI: the answer is “no”)? If not, explain how you could provide an upper and lower bound on the execution time.
Summary
Compare and contrast the micro architectures. Does it seem reasonable for the multi-cycle and pipelined implementations to have a higher clock rates than single-cycle implementations (higher in general, not necessarily the exact differences shown in the examples)? In general, how would you expect a pipelined implementation’s performance to compare to the single-cycle version?
Submission / End-of-class: Commit And Push
1. First, be sure to commit and push files to GitHub (as shown in studio)
1.1
1.2
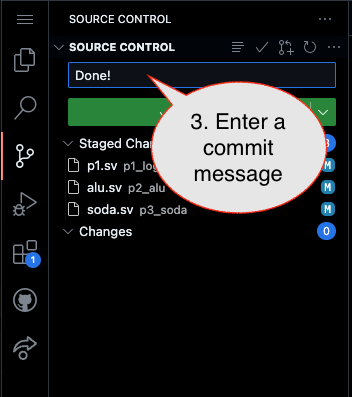
Caution!
Failure to type in a commit message will cause VSCode to open a window to enter the message (in the editor area) and the Source Control pane will appear to be stuck (a waiting animation) until you type in a message and close the message pane.
1.3
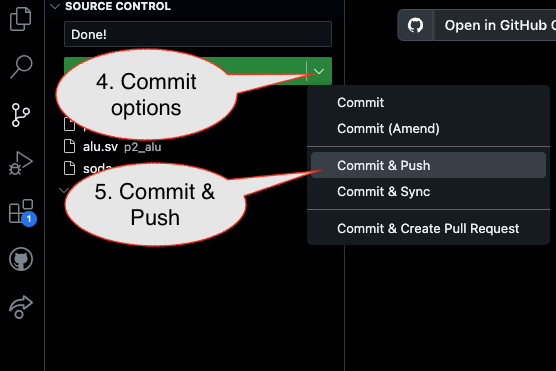
2. Then go to GitHub.com and confirm the updates are on GitHub
End of Studio: Stop the Codespace
Caution!
Be sure to “stop” your Codespace. You have approximately 60 hours of Codespace time per month. Codespaces often run for ~!5 minutes extra if tabs are just closed.